
Lorsque les chercheurs en intelligence artificielle de Google ont révélé un nouveau programme important – le Pathways Language Model (PaLM) – il y a un an, ils ont consacré plusieurs centaines de mots dans un document technique à la description des nouvelles techniques d’intelligence artificielle utilisées pour obtenir les résultats du programme.
Lors de la présentation du successeur du PaLM la semaine dernière, le PaLM 2, Google n’a presque rien révélé. Dans un seul tableau inséré dans une annexe à la fin du rapport technique de 92 pages, les chercheurs de Google décrivent très brièvement comment, cette fois-ci, ils ne diront rien :
PaLM-2 est un nouveau modèle linguistique de pointe. Nous avons des variantes petites, moyennes et grandes qui utilisent des couches empilées basées sur l’architecture Transformer, avec des paramètres variables en fonction de la taille du modèle. D’autres détails sur la taille et l’architecture du modèle ne sont pas publiés à l’extérieur de l’entreprise.
Un tournant par rapport à toute l’histoire de la publication sur l’IA
Le refus délibéré de divulguer ce que l’on appelle l’architecture du PaLM 2, c’est-à-dire la manière dont le programme est construit, n’est pas seulement en contradiction avec l’article précédent sur PaLM, mais constitue un tournant par rapport à toute l’histoire de la publication sur l’IA, qui a été principalement basée sur le code logiciel libre et qui a toujours inclus des détails substantiels sur l’architecture du programme.
Il s’agit clairement d’une réponse à l’un des principaux concurrents de Google, OpenAI, qui a stupéfié la communauté des chercheurs en avril en refusant de divulguer les détails de son dernier programme d' »IA générative », GPT-4. D’éminents spécialistes de l’IA ont averti que le choix surprenant d’OpenAI pourrait avoir un effet dissuasif sur la divulgation des informations dans l’ensemble de l’industrie, et le document PaLM 2 est le premier signe important qu’ils pourraient avoir raison.
(Il existe également un billet de blog qui résume les nouveaux éléments de PaLM 2, mais sans détails techniques).
Google fait marche arrière sur des décennies de publication ouverte
PaLM 2, comme GPT-4, est un programme d’IA générative qui peut produire des groupes de textes en réponse à des invites (prompt), ce qui lui permet d’effectuer un certain nombre de tâches telles que la réponse à des questions et le codage de logiciels.
À l’instar d’OpenAI, Google fait marche arrière sur des décennies de publication ouverte dans la recherche sur l’IA. C’est un document de recherche de Google datant de 2017, intitulé « Attention is all you need« , qui a révélé dans les moindres détails un programme révolutionnaire appelé The Transformer. Ce programme a été rapidement adopté par une grande partie de la communauté de recherche en IA, et par l’industrie, pour développer des programmes de traitement du langage naturel.
Parmi ces dérivés, le programme ChatGPT dévoilé à l’automne par OpenAI, le programme qui a déclenché l’enthousiasme mondial pour ChatGPT.
Il existe un équilibre idéal entre la quantité de données avec
lesquelles un programme d’apprentissage automatique est formé et la
taille du programme
Aucun des auteurs de l’article original, y compris Ashish Vaswani, ne figure parmi les auteurs de PaLM 2.
D’une certaine manière, en révélant dans un seul paragraphe que PaLM 2 est un descendant de The Transformer et en refusant de divulguer quoi que ce soit d’autre, les chercheurs de l’entreprise montrent clairement à la fois leur contribution au domaine et leur intention de mettre fin à cette tradition de partage des avancées de la recherche.
Le reste de l’article se concentre sur les données d’entraînement utilisées et sur les scores de référence qui permettent au programme de briller.
Ce document offre un aperçu clé, reprenant la littérature de recherche sur l’IA : il existe un équilibre idéal entre la quantité de données avec lesquelles un programme d’apprentissage automatique est formé et la taille du programme.
Les auteurs ont pu mettre le programme PaLM 2 au régime en trouvant le bon équilibre entre la taille du programme et la quantité de données d’entraînement, de sorte que le programme lui-même est beaucoup plus petit que le programme PaLM original, écrivent-ils. Cela semble important, étant donné que la tendance de l’IA a été dans la direction opposée ces derniers temps, à une échelle de plus en plus grande.
Comme l’écrivent les auteurs,
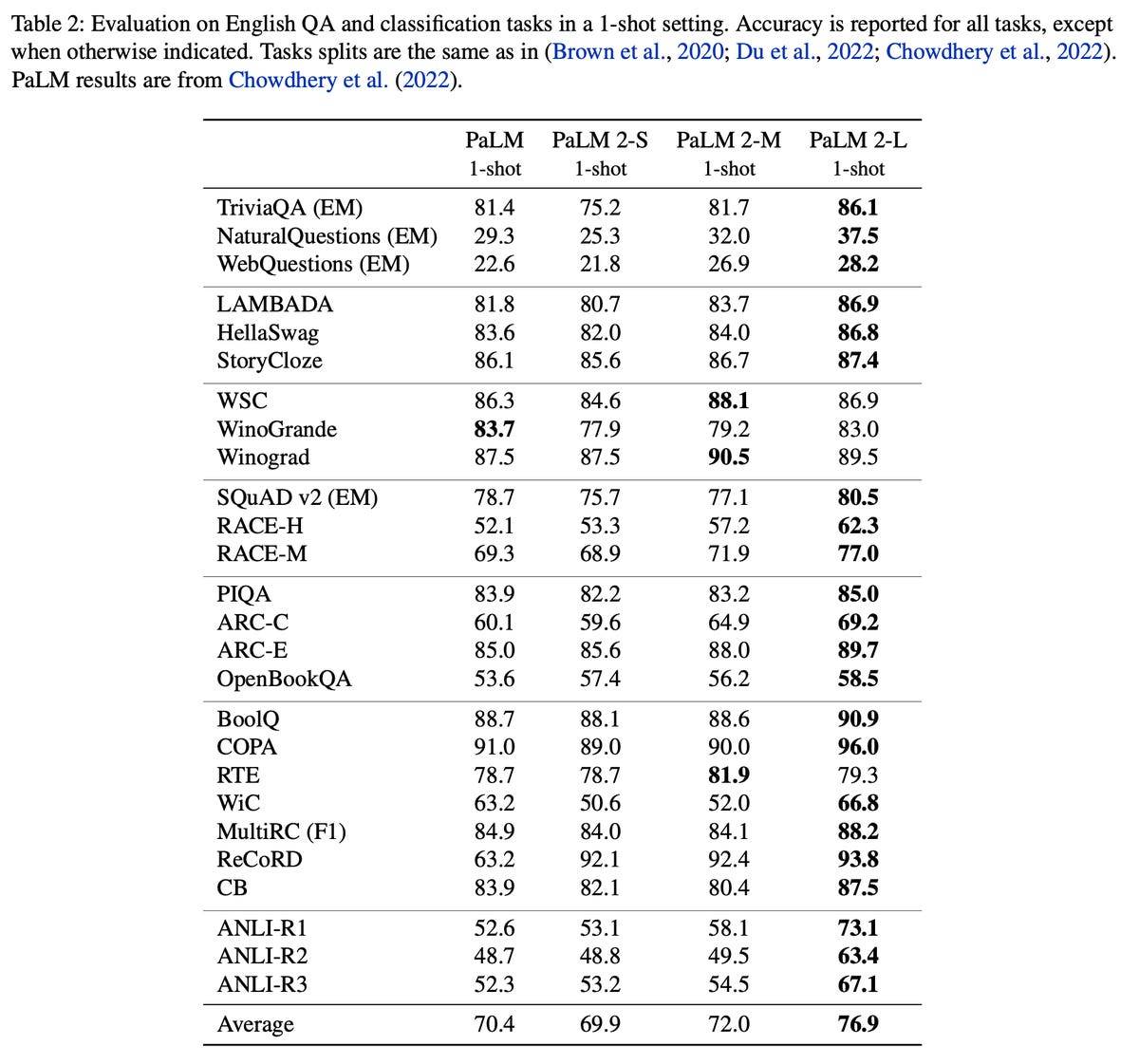
« Le plus grand modèle de la famille PaLM 2, PaLM 2-L, est nettement plus petit que le plus grand modèle PaLM, mais il utilise plus de calculs pour l’apprentissage. Nos résultats d’évaluation montrent que les modèles PaLM 2 sont nettement plus performants que les modèles PaLM dans diverses tâches, notamment la génération de langage naturel, la traduction et le raisonnement. Ces résultats suggèrent que la mise à l’échelle des modèles n’est pas le seul moyen d’améliorer les performances. Au contraire, la performance peut être débloquée par une sélection méticuleuse des données et une architecture/des objectifs efficaces. En outre, un modèle plus petit mais de meilleure qualité améliore considérablement l’efficacité de l’inférence, réduit le coût des services et permet l’application en aval du modèle pour un plus grand nombre d’applications et d’utilisateurs ».
Les auteurs de PaLM 2 affirment qu’il existe un juste milieu entre la taille du programme et la quantité de données d’apprentissage. Les programmes PaLM 2 comparés à PaLM montrent une nette amélioration de la précision dans les tests de référence, comme le soulignent les auteurs dans un seul tableau :
Google
Ils s’appuient ainsi sur les observations des deux dernières années de recherche pratique sur l’échelle des programmes d’intelligence artificielle.
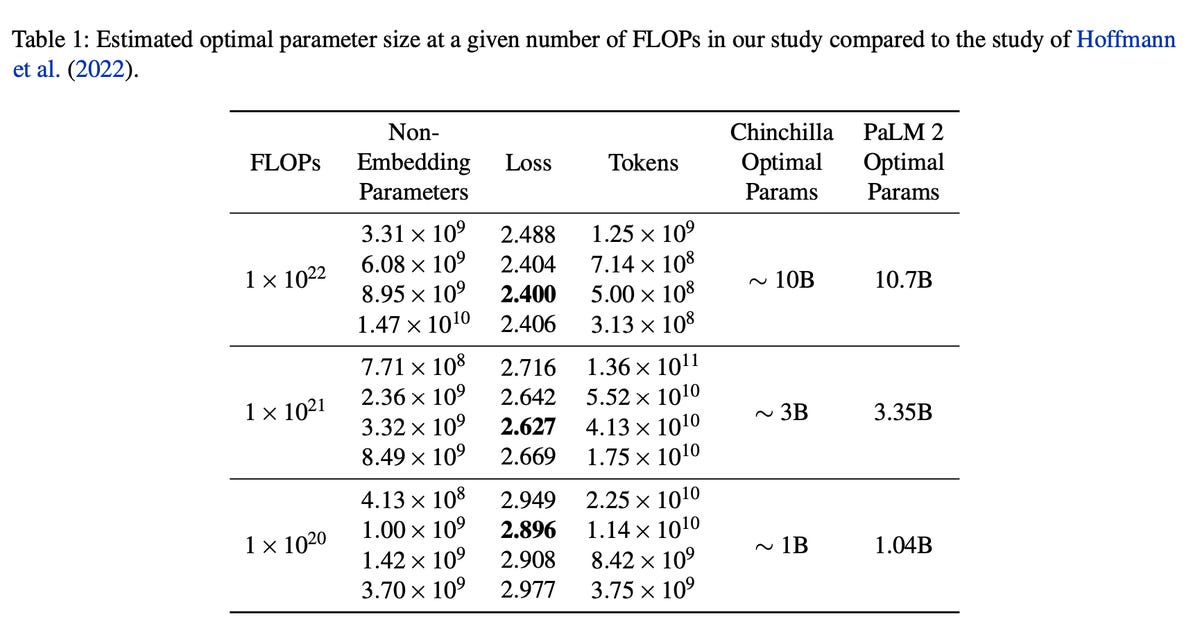
Par exemple, un travail largement cité réalisé l’année dernière par Jordan Hoffman et ses collègues au sein de DeepMind de Google a inventé ce qui est désormais connu sous le nom de règle empirique de Chinchilla, qui est la formule permettant d’équilibrer la quantité de données de formation et la taille du programme.
Les scientifiques de PaLM 2 ont obtenu des chiffres légèrement différents de ceux de Hoffman et de son équipe, mais qui confirment les conclusions de l’article. Ils présentent leurs résultats face à face avec les travaux de Chinchilla dans un seul tableau d’échelonnement :
Google
Cette idée s’inscrit dans le droit fil des efforts déployés par de jeunes entreprises telles que Snorkel, une startup d’IA de trois ans basée à San Francisco, qui a dévoilé en novembre des outils permettant d’étiqueter les données d’entraînement. Snorkel part du principe qu’une meilleure curation des données peut réduire une partie des calculs nécessaires.
L’accent mis sur le « sweet spot » s’éloigne quelque peu du modèle PaLM d’origine. Avec ce modèle, Google a souligné l’ampleur de la formation du programme, en indiquant qu’il s’agissait de « la plus grande configuration de système basée sur TPU utilisée pour la formation à ce jour », en référence aux puces informatiques TPU de Google.
Cette fois-ci, rien de tel n’est annoncé. Si peu de choses sont révélées dans le nouveau travail de PaLM 2, on peut dire qu’il confirme la tendance à s’éloigner de la taille pour le plaisir de la taille et à adopter un traitement plus réfléchi de l’échelle et de la capacité.
Source : « ZDNet.com »
Cliquez ici pour lire l’article depuis sa source.