
Le fil conducteur de la recherche en intelligence artificielle consiste à divulguer les détails techniques du logiciel dans des documents de recherche. Pourquoi ? Pour que les autres chercheurs puissent comprendre les programmes et en tirer des enseignements.
Cette tradition a été battue en brèche ce mardi avec la publication du programme GPT-4 d’OpenAI, la toute dernière technologie d’une série de programmes qui constituent le cœur du chatbot ChatGPT, extrêmement populaire. Dans le rapport technique sur GPT-4 publié mardi, ainsi que dans le billet de blog d’OpenAI, l’entreprise indique qu’elle s’abstient de fournir des détails techniques en raison de considérations liées à la concurrence et à la sécurité.
« Etant donné le paysage concurrentiel et les implications en matière de sécurité des modèles à grande échelle comme GPT-4, ce rapport ne contient pas d’autres détails sur l’architecture (y compris la taille du modèle), le matériel, le calcul d’entraînement, la construction de l’ensemble de données, la méthode d’entraînement ou d’autres éléments similaires », est-il écrit.
Le programme GPT-4 est une énigme complète
Le terme « architecture » fait référence à la construction d’un programme d’IA, à la façon dont ses neurones artificiels sont disposés, et constitue l’élément essentiel de tout programme d’IA. La « taille » d’un programme est le nombre de « poids » neuronaux, ou paramètres, qu’il utilise, un élément clé qui distingue un programme d’un autre.
Sans ces détails, le programme GPT-4 est une énigme complète.
Le document ne contient que deux phrases décrivant en termes très généraux la manière dont le programme est construit.
L’absence de divulgation est en rupture avec les habitudes des chercheurs en IA
« GPT-4 est un modèle de type Transformer préformé pour prédire le prochain mot d’un document, en utilisant à la fois des données accessibles au public (telles que les données internet) et des données sous licence de fournisseurs tiers. Le modèle a ensuite été affiné à l’aide de l’apprentissage par renforcement à partir du retour d’information humain ».
Aucune de ces deux phrases n’apporte quoi que ce soit d’intéressant.
L’absence de divulgation est en rupture avec les habitudes de la plupart des chercheurs en IA. D’autres laboratoires de recherche publient souvent non seulement des informations techniques détaillées, mais aussi le code source, afin que d’autres chercheurs puissent reproduire leurs résultats.
Un « transformer génératif pré-entraîné » bien dissimulé
L’absence de divulgation est en outre en contradiction avec les habitudes de divulgation, même limitées, d’OpenAI.
GPT-4, comme son nom l’indique, est la quatrième version de ce que l’on appelle un « transformer génératif pré-entraîné », un programme conçu pour manipuler le langage humain. Lorsque la toute première version du programme a été présentée en 2018, OpenAI n’a pas proposé de code source. L’entreprise a toutefois décrit en détail la manière dont elle a composé les différentes parties fonctionnelles de l’architecture de GPT-1.
Cette divulgation technique a permis à de nombreux chercheurs de raisonner sur le fonctionnement du programme, même s’ils ne pouvaient pas reproduire sa construction.
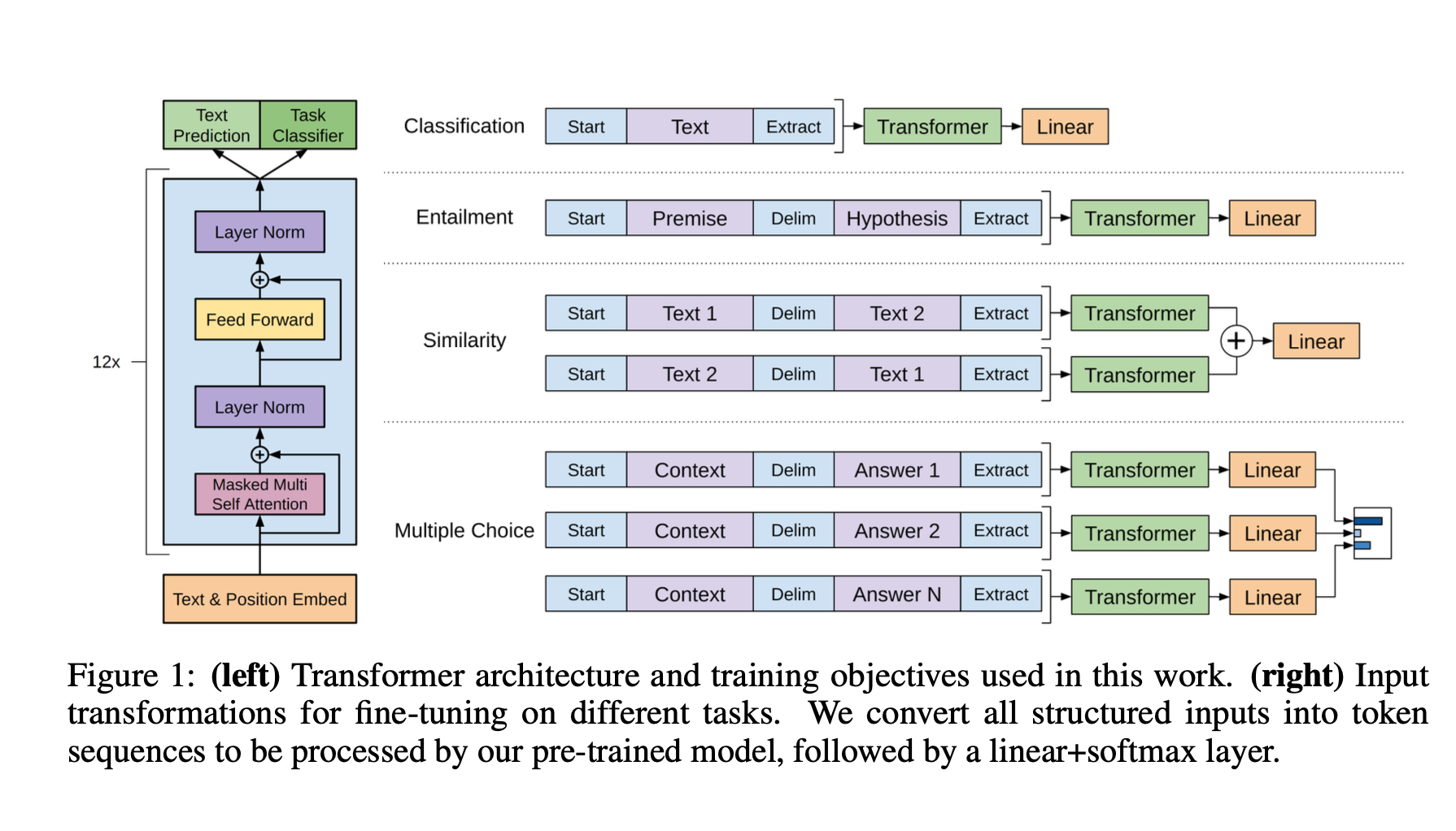
GPT-1 a été expliqué en 2018 dans un diagramme qui a permis aux chercheurs de comprendre les propriétés clés du programme. Aucune description de ce type n’apparaît dans le document technique de GPT-4. Image : OpenAI.
De moins en moins de détails
Avec GPT-2, publié le 14 février 2019, OpenAI n’a non seulement pas proposé de code source, mais a également limité la distribution du programme. L’entreprise a souligné que les capacités du programme étaient trop extrêmes pour prendre le risque que sa diffusion permette à des parties malveillantes de l’utiliser.
« En raison de nos inquiétudes concernant les applications malveillantes de la technologie, nous ne publions pas le modèle entraîné », a déclaré OpenAI.
Bien qu’ils n’aient pas publié le code ou les modèles entraînés, les chercheurs d’OpenAI, Alec Radford et son équipe, ont décrit, avec un peu moins de détails que pour la version précédente, la manière dont ils avaient modifié le premier GPT.
Le document de référence de GPT-4 marque une nouvelle étape dans l’absence de divulgation
En 2020, lorsque OpenAI a publié GPT-3, Alec Radford et son équipe ont à nouveau refusé de divulguer le code source et n’ont fourni aucun téléchargement du programme, recourant plutôt à un service cloud avec une liste d’attente. Ils ont agi ainsi, selon eux, à la fois pour limiter l’utilisation de GPT-3 par de mauvais acteurs et pour gagner de l’argent en faisant payer l’accès.
Malgré cette restriction, OpenAI a fourni un ensemble de spécifications techniques qui ont permis à d’autres de comprendre en quoi GPT-3 constituait une avancée majeure par rapport aux deux versions précédentes.
Dans ce contexte, le document de référence de GPT-4 marque une nouvelle étape dans l’absence de divulgation. La décision non seulement de ne pas divulguer le code source et le programme, mais aussi de ne pas divulguer les détails techniques qui permettraient à des chercheurs extérieurs de deviner la composition du programme, constitue un nouveau type d’omission.
Trois pages d’attribution
Bien qu’il manque de détails techniques, le document GPT-4, long de 98 pages, est cependant novateur. Il innove en reconnaissant les énormes ressources mobilisées pour faire fonctionner le programme.
Au lieu des habituelles citations d’auteurs en première page, le rapport technique contient trois pages d’attribution à la fin, citant des centaines de contributeurs, y compris tous les membres de l’OpenAI, et ce jusqu’à la direction des finances.
L’article laisse aussi entendre qu’OpenAI pourrait proposer d’autres informations à une date non précisée, et qu’elle s’est peut-être encore engagée à faire progresser la science grâce à la transparence :
« Nous sommes engagés dans l’audit indépendant de nos technologies, et nous avons partagé quelques étapes et idées initiales dans ce domaine dans la carte système qui accompagne cette version. Nous prévoyons de mettre d’autres détails techniques à la disposition d’autres tiers qui pourront nous conseiller sur la manière de mettre en balance les considérations de concurrence et de sécurité susmentionnées et la valeur scientifique d’une plus grande transparence ».
Source : ZDNet.com
Cliquez ici pour lire l’article depuis sa source.